- Student Group: Northwestern University Master of Science in Analytics (MSiA)
-
Team Members: Vincent, Varun, Jamie, Ethel, Tong, Yuqing
-
Final Poster:

- Problem statement:
Object detection and classification is significant to the functionality and safety of autonomous vehicles. Our goal was to evaluate existing models that can help autonomous vehicles improve their ability of detecting and precisely segmenting different classes of road objects. As a team, we utilized deep learning techniques to identify a sufficient model to detect and classify road objects in images captured by front-facing car cameras. We specifically focused on 6 classes of objects: car, motorcycle, bicycle, pedestrian, truck, and bus. We adapted the Mask_RCNN starter code and ran a model on a subset of our images. Then we developed our own script to evaluate the model based on IOU and MAP metrics.
- Dataset:
The dataset we used was provided by Baidu to the CVPR Workshop on Autonomous driving and Kaggle and is comprised of pictures taken by cameras mounted on two different locations on the roof of a vehicle. There are 39,223 color images in total, provided in JPEG format and occupying roughly 92GB of memory.
Each image is represented by an array of 2710 * 3384 pixels. Below are some examples from the dataset of easy, medium and hard detection/classification tasks for humans and the model: easy examples include pictures that contain objects that are close to cameras and hence take a large portion of pixels, while hard examples include images that contain few and distant objects. Medium examples are somewhere in between.
- Technical Approach:
We used an existing Mask R-CNN model trained on the COCO dataset for our road object segmentation and detection. The model detects objects in the image while generating a segmentation mask for each instance, and classifies each object.
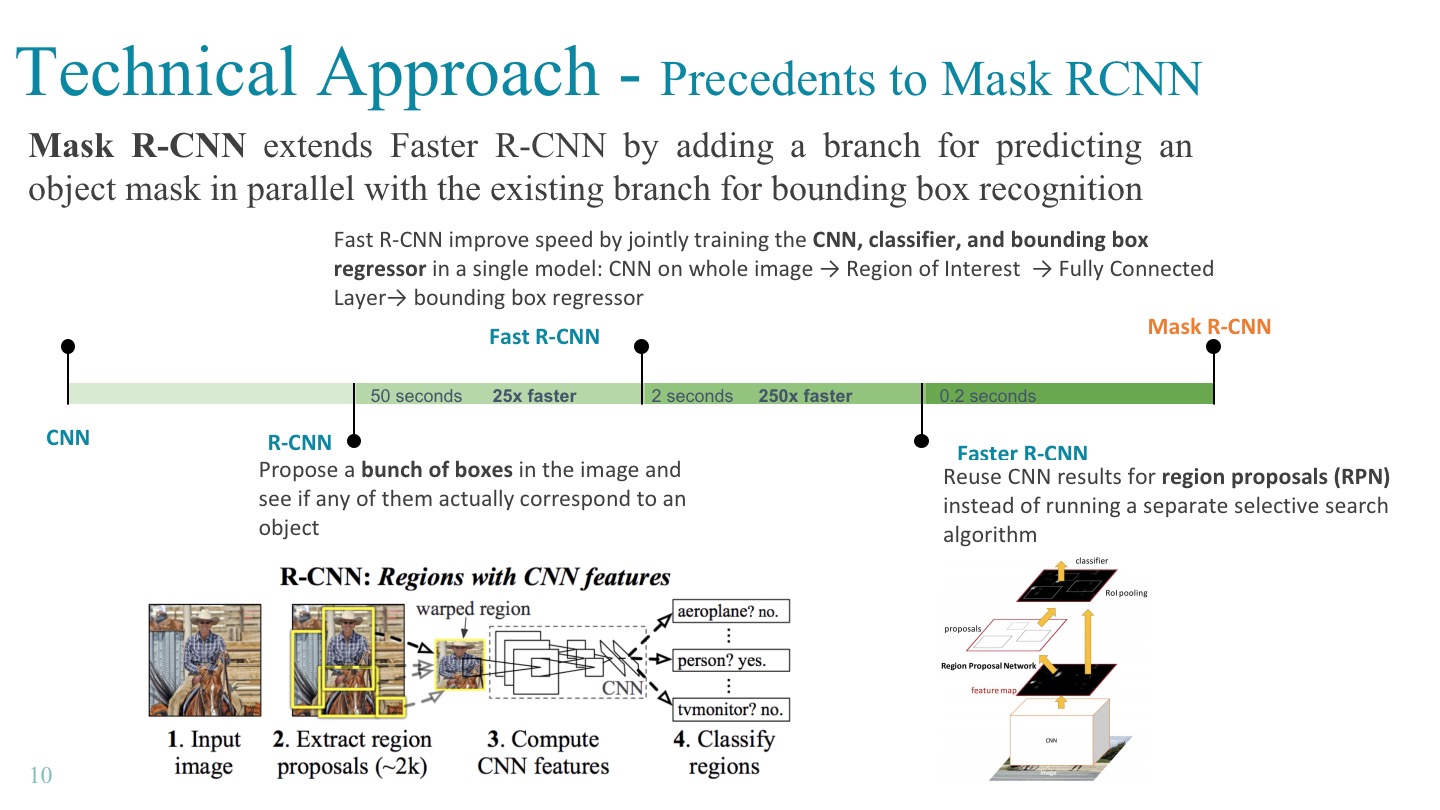
The Mask R-CNN model was invented based on R-CNN model, where R stands for “region-based”. The pipeline is that we take a picture and apply an external algorithm called selective search to it, searching for all kind of objects. Selective search is a heuristic method that extracts regions based on connectivity, color gradients, and coherence of pixels. Next, we take each region of interest(RoI) as a single image and classify with the neural network.
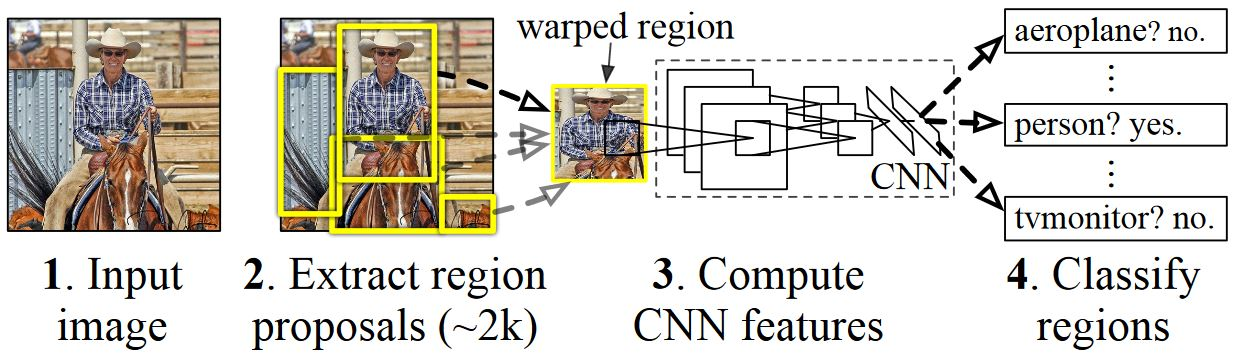
However, R-CNN worked extremely slow because it trains CNN many times separately and the top layer SVM classifiers and regressors are post-hoc. In Fast R-CNN, the procedures of CNN and region proposal are swapped. The RoI projection layer is on top of the feature map of neural network. Fast R-CNN takes the whole image through the network once, finds neurons corresponding to a particular region in the feature map in the network, and then applies the remaining part of the network to each found set of neurons. Therefore, the time consuming CNN is performed only once, and the over time to test one image can be improved 25 times faster.
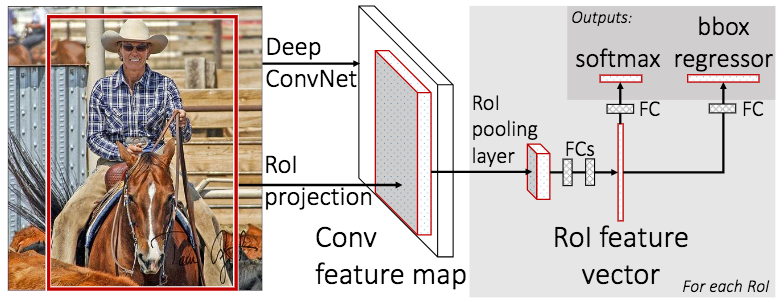
To further improve the speed and performance, the Region Proposal Network was invented to replace selective search. The Faster R-CNN model is now a complete end-to-end neural network. The top branch in the picture predicts the class of some region and the bottom branch tries to label each pixel of the region to construct a binary mask (i.e., object vs. background).
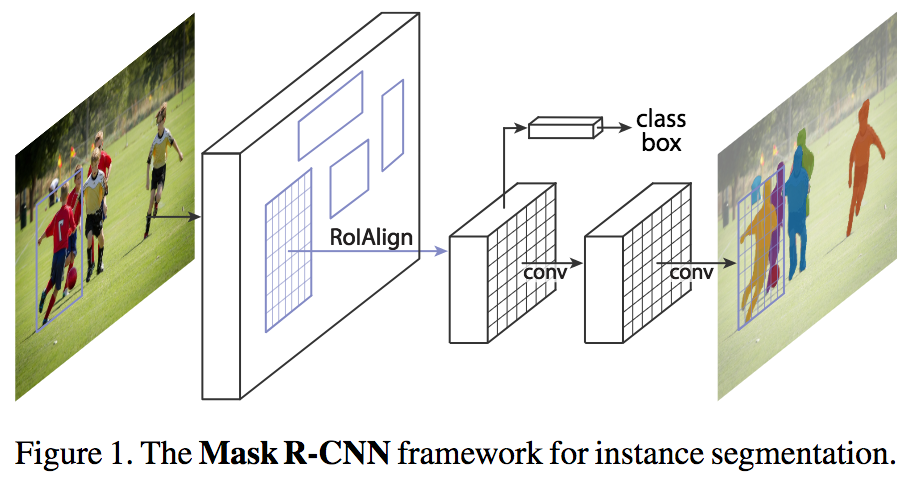
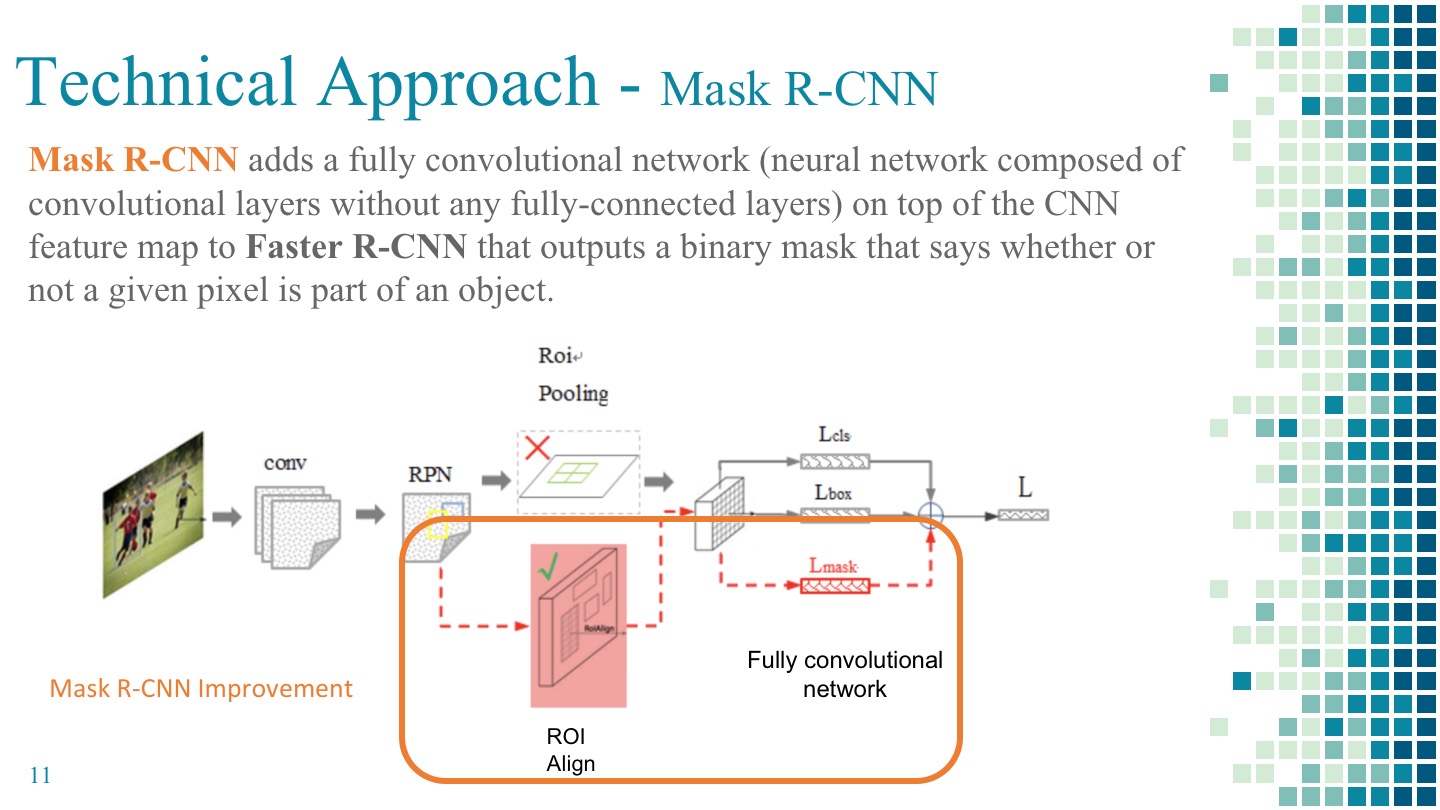
Mask R-CNN extends Faster R-CNN by adding Fully Convolutional Network(FCN) to the last step parallel with the SVM classifier and regressor. This FCN generates a binary mask that says whether or not a given pixel is part of an object and hence improve the output accuracy to pixel level. Mask R-CNN also replaces the RoI Pooling in Faster R-CNN with RoI Align which has proven to able to mitigate the misalign problem from RoI Pooling.
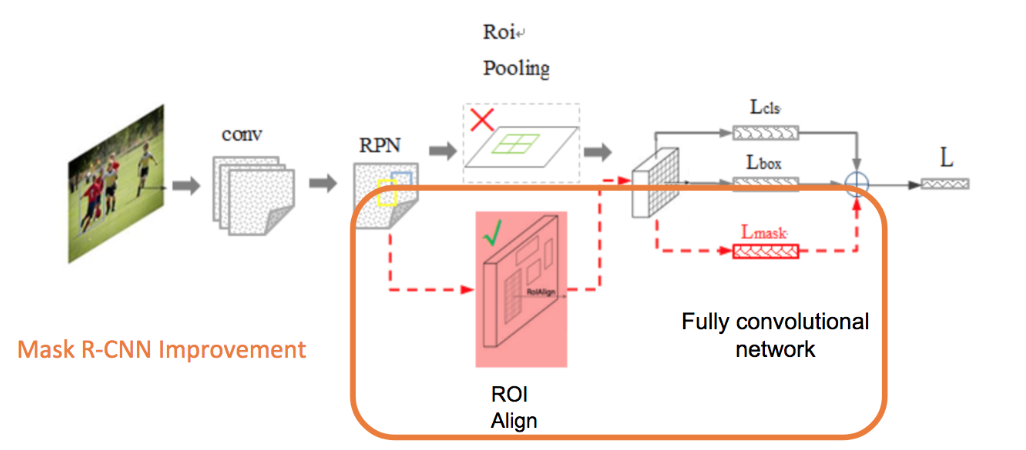
In standard deep CNNs for image classification, the last layer is usually a vector of the same size as the number of classes that shows the “scores” of different classes that could be then normalized to give class probabilities.
To get a MCP, we used the Mask R-CNN source code from its repository, and we wrote the IOU evaluation script to get the accuracy metric for each image. IOU is defined as intersection over union for each image, where the intersection is the dot product of predicted and actual object classes that matched, and union is the sum of the binary matrices where the object classes did not match.
- Results:
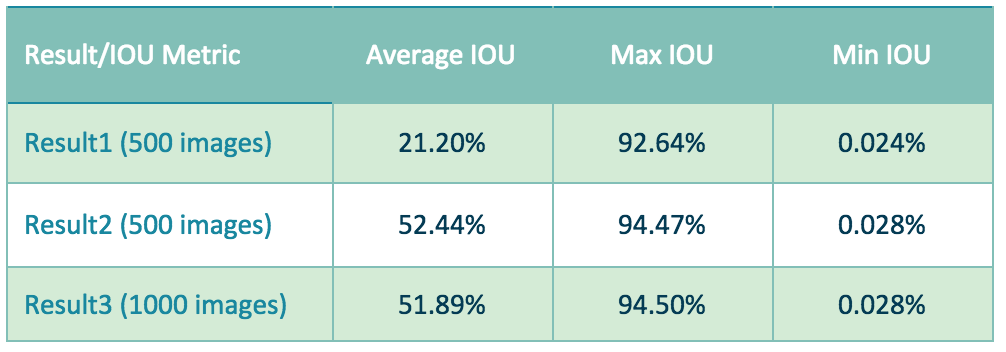
The metric we used to evaluate our result is intersection over union (IOU). We first evaluated our model on 500 images and achieved an average accuracy of 21.2%. We noticed that the cars where the cameras were mounted on were also being detected and evaluated which lowered our accuracy. We then made an improvement to crop out the cars with cameras which helped increase our accuracy on the same set of 500 images to 52.4%. We then evaluated on 500 more images and our final average IOU on 1000 images is 51.9%.
We have modified our problem to focus on only six object classes on the road to better solve the problem and identify the objects.
Below are two examples of where our model performed well and where our model didn’t perform as well. The first example has a high accuracy of 87% and as the masks show that all but one class (person) were correctly identified. The green mask on the truck had the largest pixel values which also helped with the accuracy. The second example has a low accuracy of less than 1% and the reason was that the stream of sunlight was misidentified as a person and there were not many objects to start with so the chance of misidentification is high.

We did have enough data (testing images) but because of limited computing resources and time constraint, we were not able to run our model on the entire test image dataset and evaluate the results. Therefore, we chose a subset of the first 1000 images to focus on.
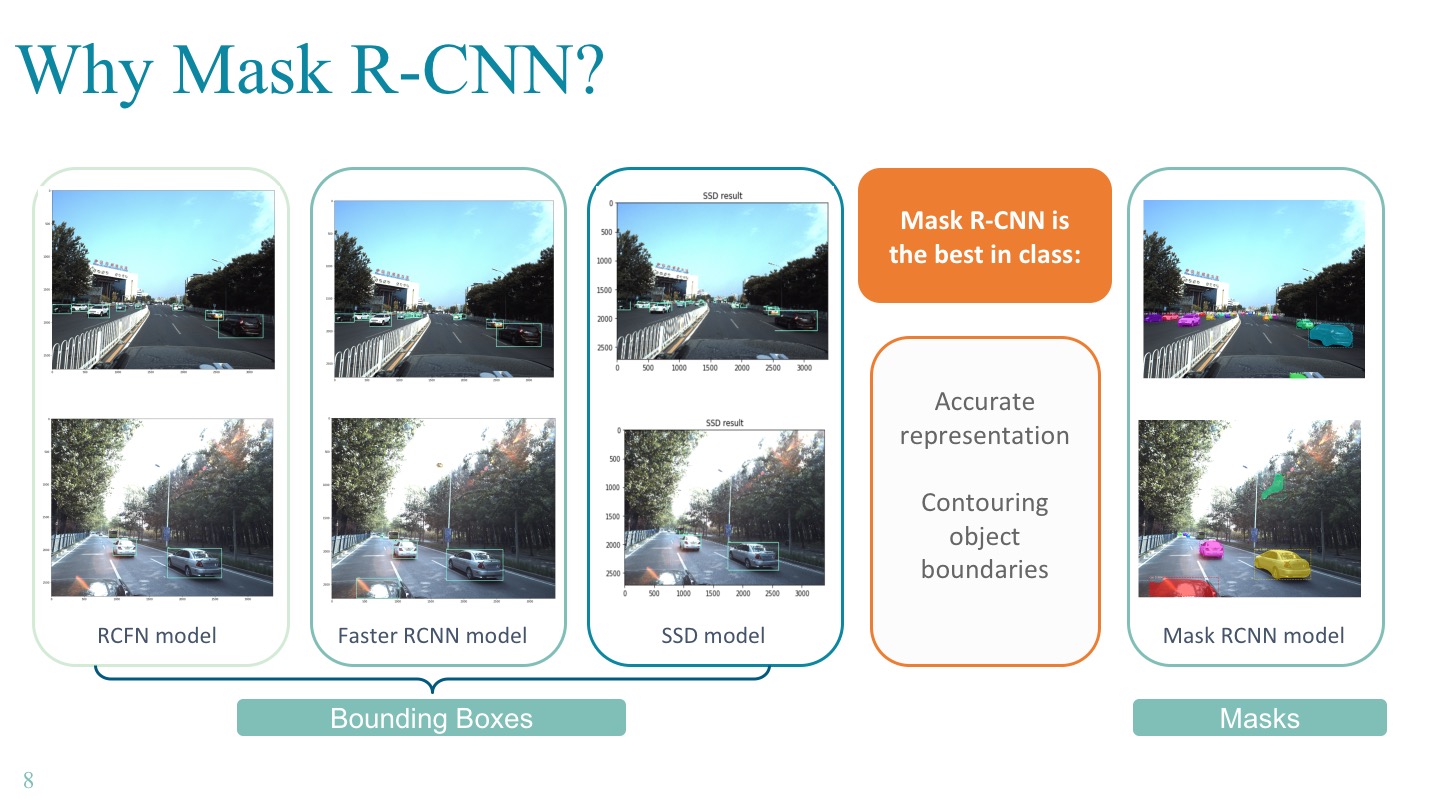
We know we have found the best model after comparing the model output with the output from other object detection and classification models. The models that we tried and examples of each of their output are listed below:
 As in seen in the examples table above, it is clear that the Mask R-CNN model can detect more objects and thus have higher accuracy.
As in seen in the examples table above, it is clear that the Mask R-CNN model can detect more objects and thus have higher accuracy.
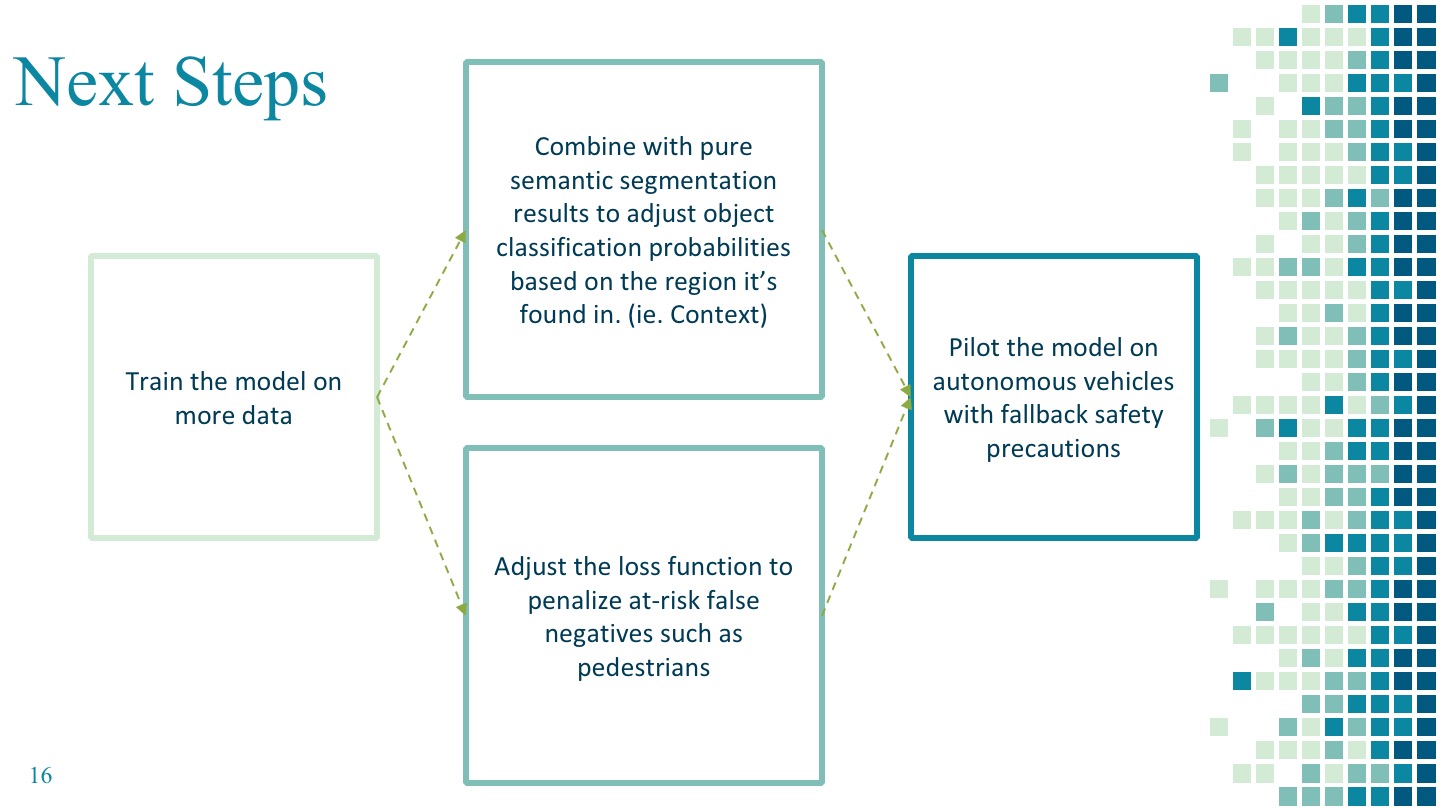
- Concluding remarks and future work:
At the moment the work we have done is not sufficient to be deployed in a commercial environment, as there are still a number of challenges that we faced. Firstly, since we only tested the model on a subset of 1000 images given the time and computational resources we had, we would need to test the model on many more images in order to get more robust performance results. Secondly, although the Mask R-CNN model yields a promising average accuracy measured by IoU and illuminates a bright future for autonomous vehicle driving, a high overall accuracy does not equate to road safety; there are many cases where human drivers outperform machines in detecting objects on the road.
Machine learning is based on trial and error and includes supervised and unsupervised methods. Machine learning can run on low-end devices and breaks down a problem into parts where each part is solved in order and then combined to create a single answer/interpretation to the problem. Deep learning is basically machine learning but on a deeper level and requires large data and high-end devices/computing resources. We felt it was worthwhile to learn deep learning especially when working with large image datasets, and the more data and time we feed a deep learning algorithm, the better results the network will get.
We believe one of the main advantages of Deep Learning is that it gets better the more data we feed into it, while traditional machine learning algorithms normally reach a level where more data does not help to improve the performance. So Deep Learning will be very likely to come into play when we are going to deal with massive amounts of data in jobs and internships. If the market is not so ready for Deep Learning, we think the amount of data required to train such models as well as the computational costs involved would certainly be some concerns.
For road object detection, high and accurate classification rate is preferred over high degree of model explainability, given that our main goal is to correctly detect different classes of objects on the road to improve the performance of autonomous driving. If the model can be proven to generalize well simply through experimentation, that is sufficient, even if it isn’t easy to explain how it achieves its results. If Deep Learning was being used to make driving decisions as well, explainability would become much more significant.
- References:
Mask R-CNN – Facebook AI Research (FAIR) Image segmentation with Mask R-CNN – Jonathan Hui – Medium CS231n: Convolutional Neural Networks for Visual Recognition – Stanford University NeuroNuggets: Segmentation with Mask R-CNN – Sergey Nikolenko A Brief History of CNNs in Image Segmentation: From R-CNN to Mask R-CNN – Dhruv Parthasarathy A 2017 Guide to Semantic Segmentation with Deep Learning – Sasank Chilamkurthy