
- Student Group: Northwestern University Master of Science in Analytics (MSiA)
- Team Members: Vincent Wang
- Client: Yelp
1. Purpose and Objectives
- Using NLP to do user rating prediction based on customer reviews,
- Classification model to predict the successfulness of the rating (5 and no5).
- Cluster users review key words to find out the hidden user ‘preference.
- Understand the customer emotions through sentiment analysis (token coefficient from logistic regression)
- Propose a recommendation systems.
2. Dataset
- The Challenge Dataset:
- 4.1M reviews and 947K tips by 1M users for 144K businesses
- 1.1M business attributes, e.g., hours, parking availability, ambience.
- Aggregated check-ins over time for each of the 125K businesses
- 200,000 pictures from the included businesses
- Cities:
- U.S.: Pittsburgh, Charlotte, Urbana-Champaign, Phoenix, Las Vegas, Madison, Cleveland
- Files:
- yelp_academic_dataset_business.json
- yelp_academic_dataset_review.json
3. Data Cleansing
- Load the business and review data into pandas data frame.
- Sampling
- Create filters that selects the most interesting business that are located in “Las Vegas” that contains “Restaurants” in their category (You may need to filter null categories first)
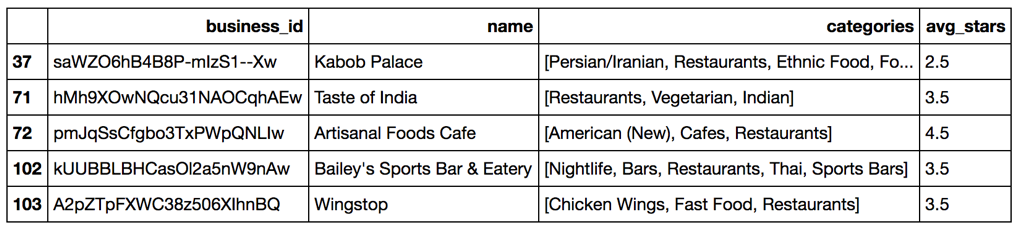
- Keep relevant columns
- business_id
- name
- categories
- stars
-
Then, load the review data:

- Join two table and set id as index
- We further filter data
- by date, e.g. keep comments from last 2 years
- Otherwise your laptop may crush on memory when running machine learning algorithms
- Purposefully ignoring the reviews made too long time ago
4. NLP
- Define your feature variables
- here is the text of the review
- “The food was decent, but the service was definitely sub par (especially for the price!).It took 15-20 minutes for the server to acknowledge us just so that we order drinks. Our dinner was good but I have to say that I was disappointed that they did nothing to acknowledge my birthday celebration. We chose this restaurant over STK & CUT to celebrate the occasion and I wish we hadn’t. They did nothing to acknowledge our occasion which was sad. I will not be going back to this restaurant again.”
- Text Processing
- The first thing we need to do is process our text. Common steps include:
- Lower all of your text
- Strip out misc. spacing and punctuation
- Remove stop words
- Stop words are words which have no real meaning but make the sentence grammatically correct.
- Words like ‘am’, ‘the’, ‘my’, ‘to’, & c. NLTK contains 153 words for the English set of stop words These can also be domain specific.
- Stem/Lemmatize our text
- he goal of this process is to transform a word into its base form.
- e.g. “ran”, “runs” -> “run” You can think of the base form as what you would look up in a dictionary Popular techniques include stemming and lemmatization.
- Stemming removes the suffix whereas
- Lemmatization attempt to change all forms of the word to the same form.
- Stemmers tend to operate on a single word without knowledge of the overall context. These are not perfect, however (e.g. taking the lemma of “Paris” and getting “pari”)
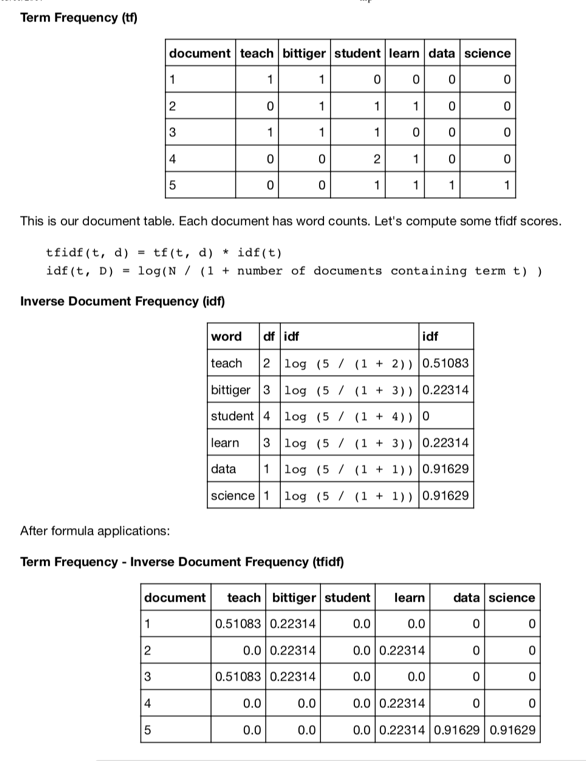
- Text Vectorization Term Frequency
- We must convert our text data into something that these algorithms can work with by converting our corpus of text data into some form of numeric matrix representation.
- The most simple form of numeric representation is called a Term- Frequency (https://en.wikipedia.org/wiki/Document-term_matrix) matrix
- Each column of the matrix is a word, each row is a document, and each cell represents the count of that word in a document.
- Let’s start with the flow:
- Tokenization —-> Sentence segmentation —-> Stemming/Lemmatization —-> stop words —-> Bag of words/TFIDF
- Tokenization
- ‘I’, ‘banked’, ‘on’, ‘going’, ‘to’, ‘the’, ‘river’, ‘bank’, ‘today’, ‘.’
- Document Creation
- A document is a list of lists where each list is a list of strings that contains one token.
- ‘I’, ‘banked’, ‘on’, ‘going’, ‘to’, ‘the’, ‘river’, ‘bank’, ‘today’, ‘.’
- Lower case
- ‘i’, ‘banked’, ‘on’, ‘going’, ‘to’, ‘the’, ‘river’, ‘bank’, ‘today’, ‘.’
- Stemming/Lemmatization
- ‘i’, ‘bank’, ‘on’, ‘go’, ‘to’, ‘the’, ‘river’, ‘bank’, ‘today’, ‘.’
- Remove stop words
- ‘bank’, ‘go’, ‘river’, ‘bank’, ‘today’, ‘.’
- Define your target variable
- any categorical variable that may be meaningful
- For example, I am interested in perfect (5 stars) and imperfect (1-4 stars) rating
- You may want to look at the statistic of the target variable
- Let’s create training dataset and test dataset
- Let’s get NLP representation of the documents
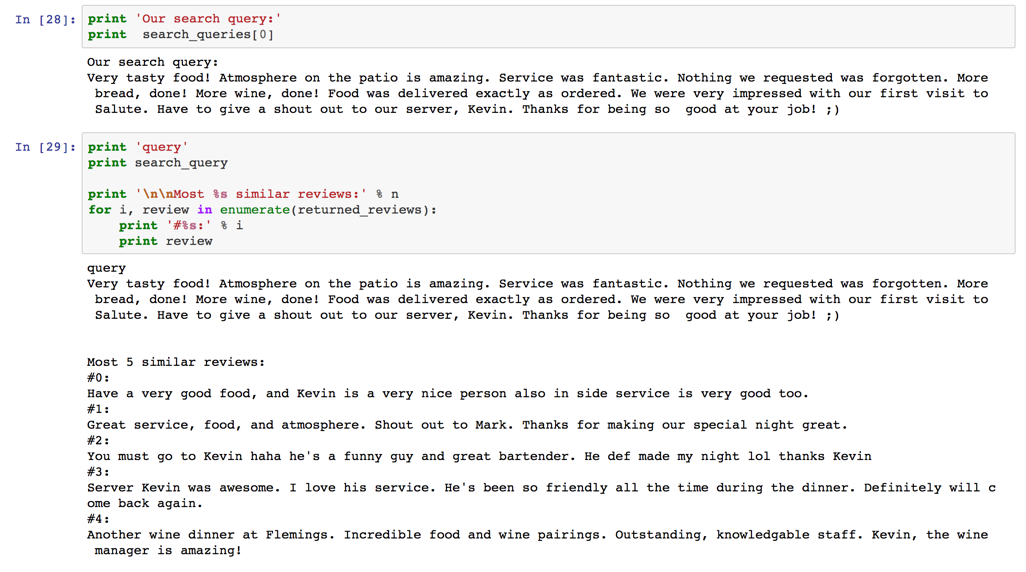
- Similar review search engine
- Select the query review,
- Vectorise it to have the same format with other review pool.
- Calculate the cosine similarity with every review in the review pools.
- Cosine and Euclidian distance (Distance among documents)
- Sort the result and choose top 5 reviews have least distance.
- Classifying positive/negative review
- Target: two group (favorite 5stars, unfavorite no 5 stars)
- Vector: review data (vector transformed)
- Metric: accuracy
- Naive-Bayes Classifier
- Logistic Regression Classifier
- Variable coefficient can show positive/negative influence to the model
- Positive: u’amazing’,u’best’,u’awesome’,u’perfect’,u’thank’,u’delicious’,u’highly’
- Negative: u’worst’,u’ok’,u’rude’,u’horrible’,u’bland’,u’slow’,u’terrible’
- Random Forest Classifier
- Clustering
- Cluster the review text data for all the restaurants
- Define your feature variables, here is the text of the review
- Define your target variable (any categorical variable that may be meaningful) (ratings, types)
- For example, I am interested in perfect (5 stars) and imperfect (1-4 stars) rating¶
- Cluster the text file based on other variables
- Get NLP representation of the documents
- Fit TfidfVectorizer with training data only, then tranform all the data to tf-idf¶
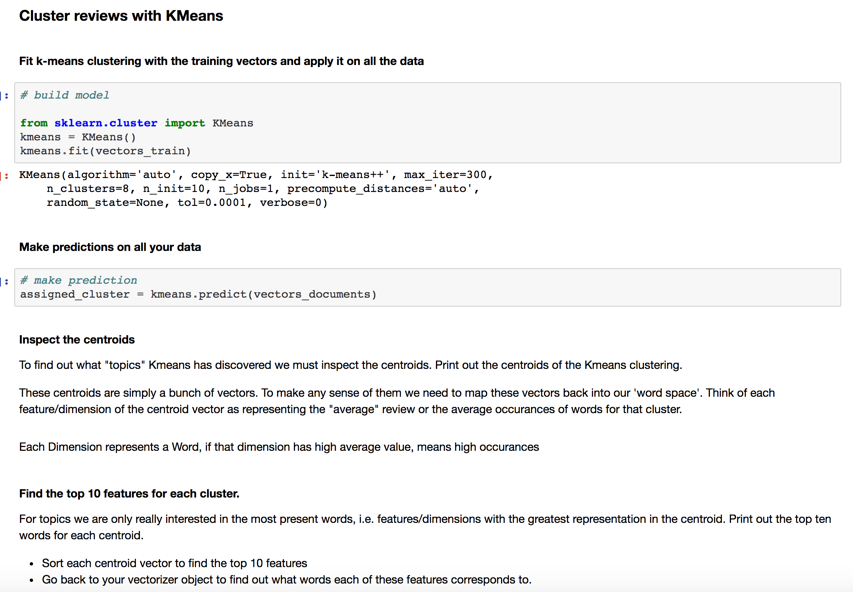
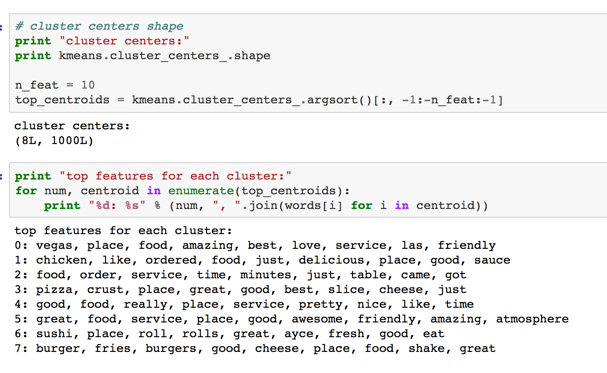
- k means clustering, 8 groups, similar words in each group.
- Cluster all the reviews of the most reviewed restaurant
- Let’s find the most reviewed restaurant and analyze its reviews
- Vectorize the text feature
- Define your target variable (for later classification use)
- Cluster the review text data for all the restaurants
- Recommendation Systems:
- Get business_id, user_id, stars for recommender
- Create utility matrix from records
- Convert to document, word like matrix
- recommendation system with graphlab
- built the utility matrix
- extract some and quantify slme features of the resturants.
- Content-based recommender
- extract some feature for recommender
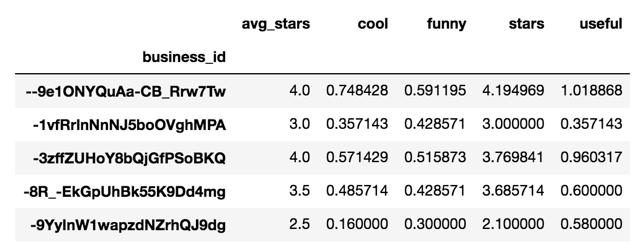
- extract some feature for recommender
- item and categories
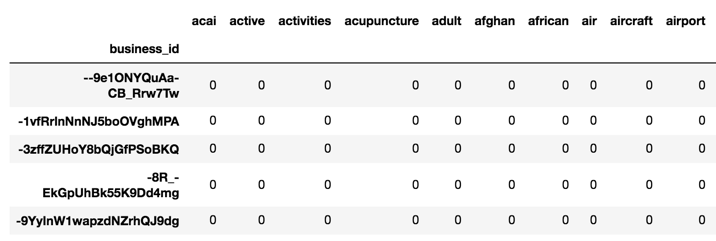
- Popularity-based recommender
- built the utility matrix